CQRS——命令查询职责分离
CQRS 表示命令查询职责分离(Command Query Resposibility Segregation)。它是一种设计模式,我是第一次从 Greg Young 那里听说的。其核心在于你可以使用不同于你使用读的模型的模型来更新信息。在一些情况下,这种分离是有价值的,但是要注意,这对于大部分系统来说会增加风险复杂性。
主流方法是人们使用 CURD 数据存储来与信息系统交互。我的意思是我们有一些记录结构,它能让我们创建新记录,读记录,更新存在的记录,以及删除记录。最简单的情况下,我们的交互都是关于存储与检索这些记录。
当我们的需求变得越来越复杂时,我们就逐渐原理了这种模式了。我们可能希望以不同的记录存储方式查看信息,可能会将多个记录合并为一个记录,或者通过在组合不同的地方的信息构成一个虚拟记录。在更新方面,我们可能会发现验证规只允许存储特定的某些特定组合数据,甚至推断出存储的数据与我们提供的数据不同。
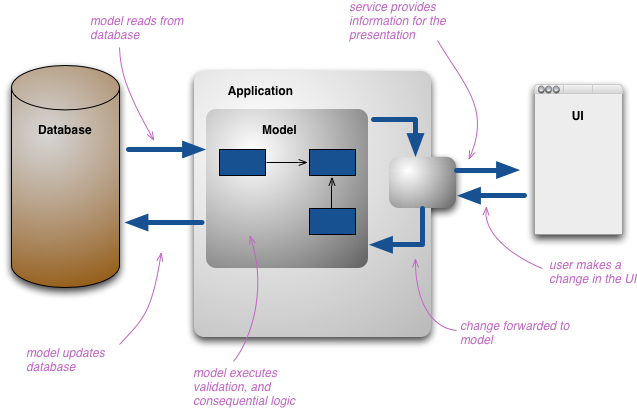
当这样发生时,我们开始看到信息的多种表现形式。当用户与信息交互时,他们使用各种信息的表现形式,它们表现的每一个都不同。开发者指定生成他们自己的具体模型,用来操作这些模型的核心元素。如果你正在使用领域模型,那么这通常在概念上会表现领域。你通常还会使持久存储尽可能的接近概念模型。
这种多层表示的结构会更加复杂,但是当人们这样做的时候,任然会去分解它成为一个单一概念表示,在所有的表示层之间作为一个概念集成点。
CQRS 引入的更改是将概念模型拆分为单独的模型作为更改和展示,它按照 命令和查询分离 词汇显示为 Command 和 Query。基本原理是对于大多数问题,特别是越来越复杂的领域里,对命令和查询使用相同概念模型会导致更复杂的模型,而这两种模型都做得不好。
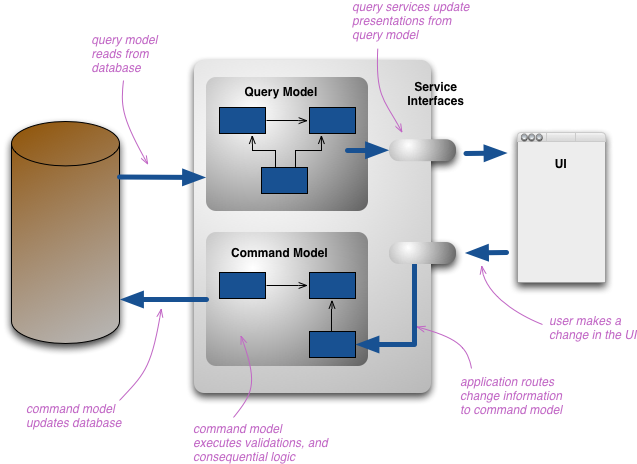
我们通常所说的分离模型是指不同的对象模型,可能运行在不同的逻辑处理中,也许在独立的硬件中。一个网页例子是用户查看使用查询模型渲染出来的网页。如果他们开始改变,这个改变被路由到单独的命令模型来处理,这结果改变就是传达给查询模型来渲染更新状态。
这里有相当大的变化空间。内存模型也许会共享相同的数据库,在这种情况下,数据库就在两个模型之间传递。然而他们有可能使用各自使用独立的数据库,有效地使查询端数据库成为实时报告数据库。在这种情况下,在两个模型或他们数据库之间需要一些沟通机制。
这两个模型也许不会独立的对象模型,相同对象在他们命令端和查询端而言有不同的接口,而不是像关系型数据库展示的一样。但通常当我听到 CQRS 时,他们是被明确为独立的模型。
CQRS 很自然地适合其他一些架构模式。
- 当我们通过 CRUD 与之交互来从单一表示远离时,我们能很容易地转移到基于任务的 UI。
- CQRS 能很好的适合基于事件编程模型。通常是说 CQRS 系统分隔为单服务来与 Event Collaboration 沟通。它允许这些服务很容易的利用事件源的优势。
- 对于大多数领域,更新时需要很多逻辑,所以使用 EagerReadDerivation 来简化你的查询端模型就很有意义了。
- 对于所有的更新,如果写模型生成事件,你能组织读取的模型作为 EventPosters,允许它们成为 MemoryImage 并且避免了数据库的交互。
- CQRS 对于复杂领域是很合适的,这种类型也收益与驱动领域设计
何时使用它
就像任何模式,CQRS 在一些地方很有用,但是在其他方面却不是如此。很多系统合适使用 CURD 模型,并且在这种模式下是对的。CQRS 对于所有相关的人来说都是一个重大的飞跃,所以不应该被解决,除非好处非常大。当我使用过 CQRS 成功过,但到目前为止,大多数使用都不是很好,CQRS 被认为是使软件系统陷入严重困境的重要力量。
特别地,CQRS 应该只被用在一个系统的特殊部分(DDD 术语中的边界上下文)而不是应用在整个系统。以这种方式思考,每个边界上下文都需要自己决定怎样建模。
到目前为止,我看到两个方面的好处。第一是少许复杂的领域也许更容易通过 CQRS 解决。然而,我必须强调,这种适合 CQRS 的情况非常少。通常在命令和查询端之间有足够的重叠,那么共享模型将会更加容易。在领域使用 CQRS 毫无疑问会增加复杂性,从而降低了生产力和增加了风险。
另一主要的好处是在处理高性能应用程序中。CQRS 允许你单独从读操作加载,以及允许扫描每一个依赖来进行写操作。如果你的应用程序在读写之间的差异非常大,那么这会非常有用。即使没有,你能在两端应用不同优化策略。一个例子是使用不同的数据库读写访问技术。
如果你的领域不适合 CQRS 模式,但是你又有查询的需求,这样会带来复杂性或性能问题,要记得你任然可以使用 报表数据库。CQRS 是为所有的查询使用一个单独的模型。而对于报表数据库,你还是可以在大多数查询中使用,但是这样一来,就把更多的复杂需求带给了报表数据库。
考虑到这些因素,你必须应该慎用 CRQS。很多信息系统都很符合信息库的概念,它更新的方式与读取的方式相同,这种类似的系统加入 CQRS 会带来严重的复杂性。我当然见过这种情况,它严重的影响了生产力,给项目带来了不必要的很多风险,即使在一个很有能力的团队里也是如此。虽然 CQRS 是一个很好的模式,但是要小心,它是很难用好的,一旦你稍微不注意就会犯下很严重的错。
原文连接
https://martinfowler.com/bliki/CQRS.html